
이번 시간엔, 자바의 컬렉션프레임워크에 대해 알아보자.
아래 그림과 같이 Iterable객체를 상속받은 Collection을 기반으로 다양한 컬렉션들이 존재한다. 대표적으론 List, Set, Map, Queue가 있다.

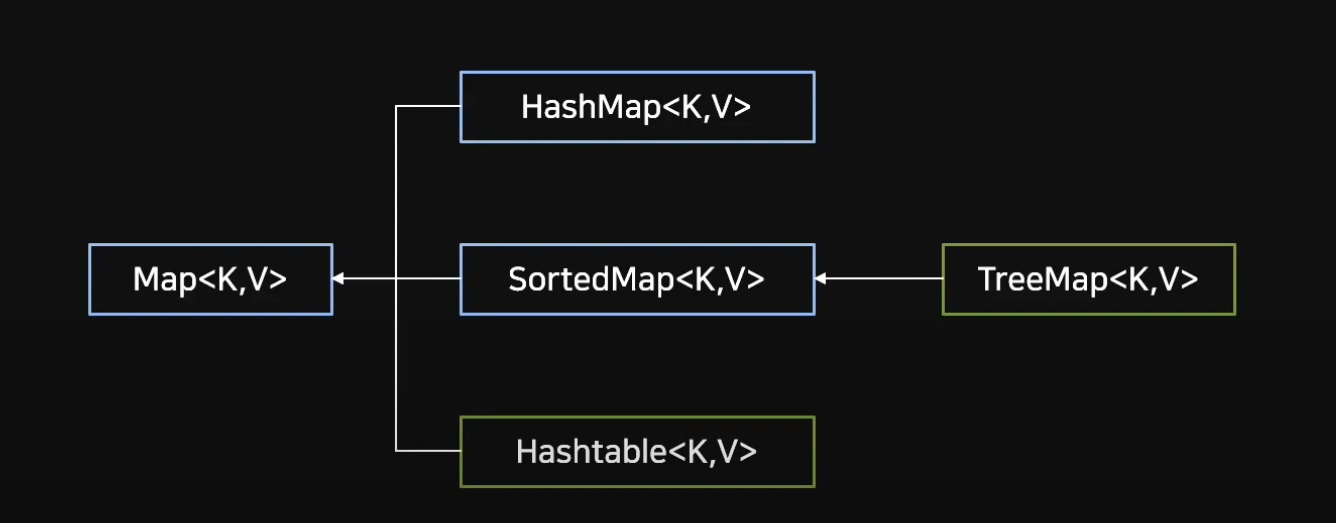
아래 그림외에도, Map이라는 컬렉션 또한 존재하는데 해당 컬렉션은 <Key, Value>로 이루어진 특별한 구조로 인해 별개로 구분한다.
List 인터페이스
순서 개념이 있는 데이터의 집합을 의미함. 순서가 존재하며 데이터의 중복저장이 가능하다.
이를 구현한 구현체로는 ArrayList, LinkedList, Vector, Stack이 존재한다.(Stack도 리스트 기반인줄은 .. 몰랐다)
ArrayList
내부적 배열을 기반한 단방향 포인터 구조로, 각 데이터의 인덱스가 존재한다. 내부적으로 배열을 이용하기에 크기조정을 하기 위해선 크기가 다른 배열을 생성하고 재배정하는 과정을 거친다.
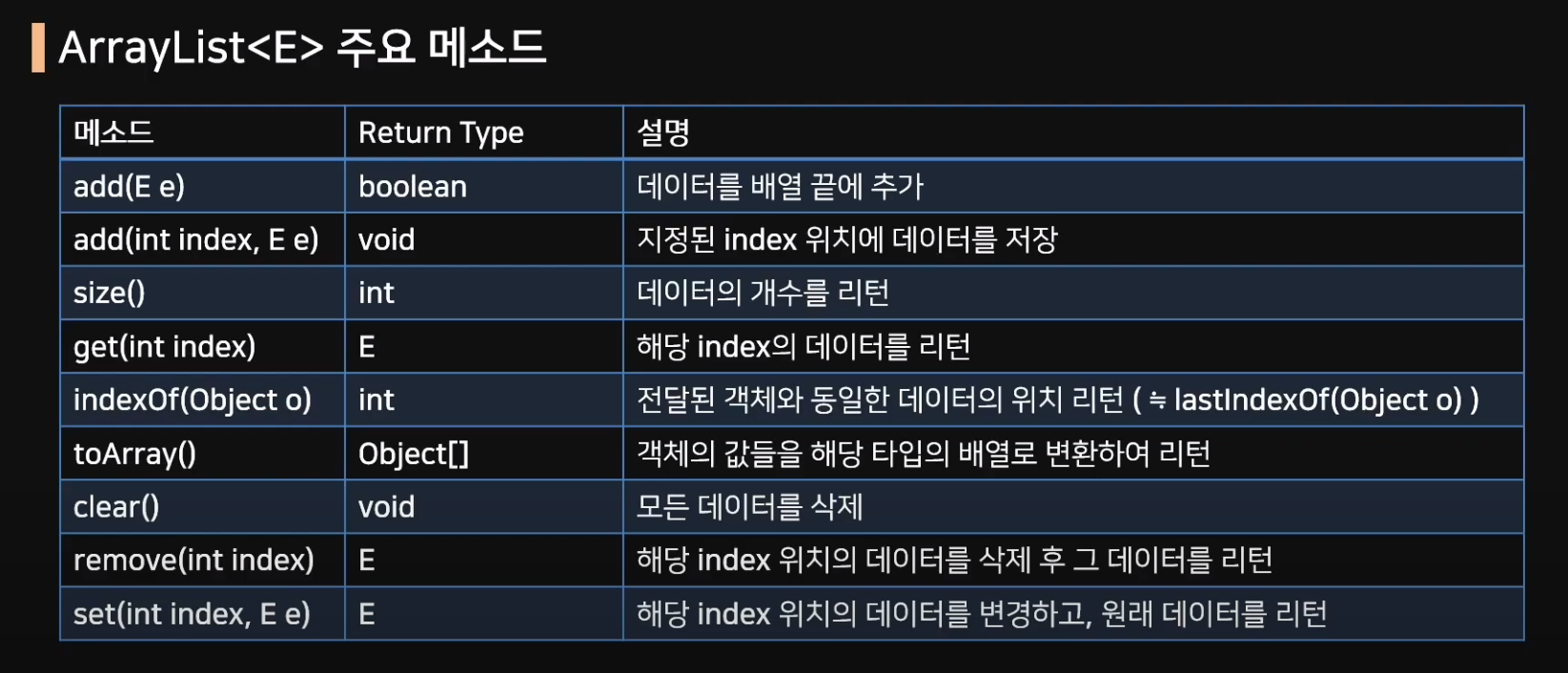
주요 메서드는 아래 사진과 같은데 add메서드가 두 개 존재한다.
add(E e): 데이터를 끝에 추가하고 성공하면 true를 반환함
add(int index, E e): 데이터를 index번째 배열에 저장한다.
indexOf(E e): 해당 값이 존재하는 인덱스를 반환함.
LinkedList
노드끼리 연결된 연결리스트. List의 특징인 순서, 중복저장이 가능하다는 특징이 있다.
연결리스트인지라 중간에 데이터를 삽입/삭제하는데에 용이하지만 상대적으로 데이터를 조회하는데 속도가 느리다는 단점이 있다.
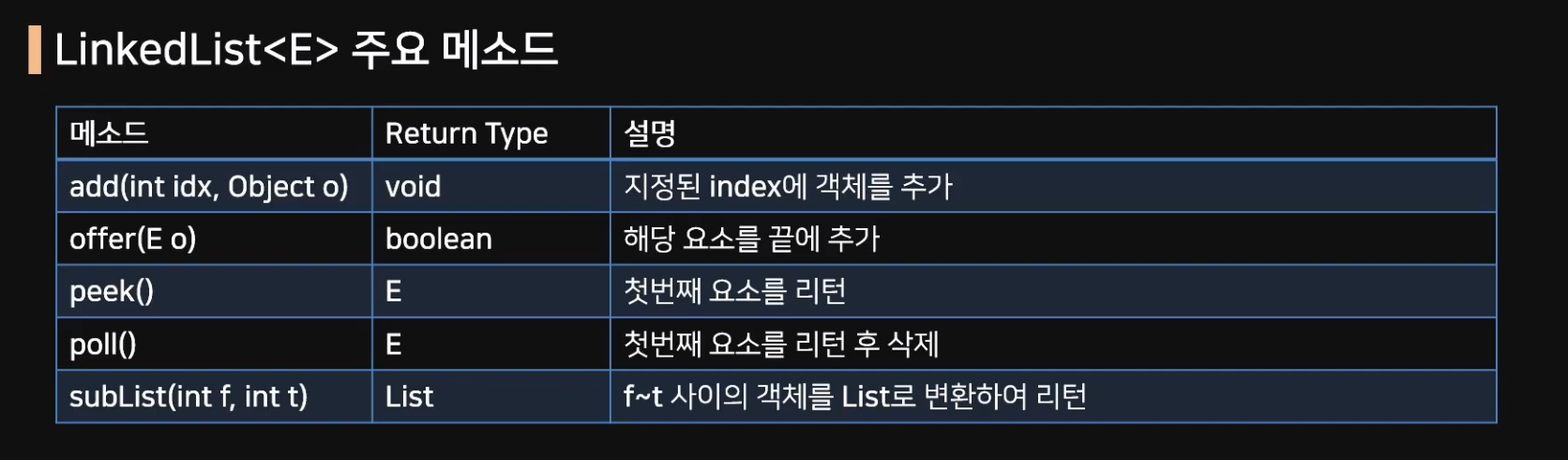
주요 메서드는 아래와 같은데 poll 메서드는 후에 삭제, peek은 보고끝!!을 기억하자.
offer(E o): 해당 값을 링크드리스트 끝에 ㅜㅊ가
peek(): 첫번째 요소를 리턴
poll(): 첫번쨰 요소를 리턴 후 삭제
Vector
기본적으로 ArrayList와 동일하다고 하다. 그러나, 여러개의 스레드가 데이터에 접근할때마다 동기화를 해주기에 Thread Safe하다는 특징을 가지고 있다.
물론, 스레드가 하나일때도 동기화가 진행되어 이 경우엔 성능이 저하된다.
capacity(): 벡터의 물리적인 크기를 반환한다. 메모리라고 생각했는데 기본 값이 10인것으로 보아 그건 아니다. 잘 쓰지 않는다고 한다!
Stack
후입 선출의 구조, 자료를 차례대로 넣고 뺄때는 나중에 넣은 값이 먼저 반환된다.
주요 메서드는 다음과 같은데 push, pop은 C++과 동일하지만 peek에 주목하자.
peek(): Stack에 마지막 요소를 리턴하고 끝 : 사실상 top()과 동일
pop(): Stack의 마지막 요소를 리턴하고 삭제
add()를 사용하기도 하는데 add는 boolean을 반환하고 push는 내가 입력한 파라미터를 반환한다는 것에도 주목하자. return type의 차이이다.
위의 자료들을 정렬하기 위해선 Collections에 sort함수를 사용하면 되며 기본적으론 오름차순으로 정렬한다.
Vector<String> vector = new Vector<>();
System.out.println(vector.capacity());
vector.add("가");
vector.add("다");
vector.add("나");
Collections.sort(vector);
for (String s: vector ) {
System.out.println(s);
}
Queue 인터페이스
Queue는 대기열과 같은 선입선출 구조로 데이터를 일시적으로 쌓아둔다.
LinkedList를 활용하여 생성한다.
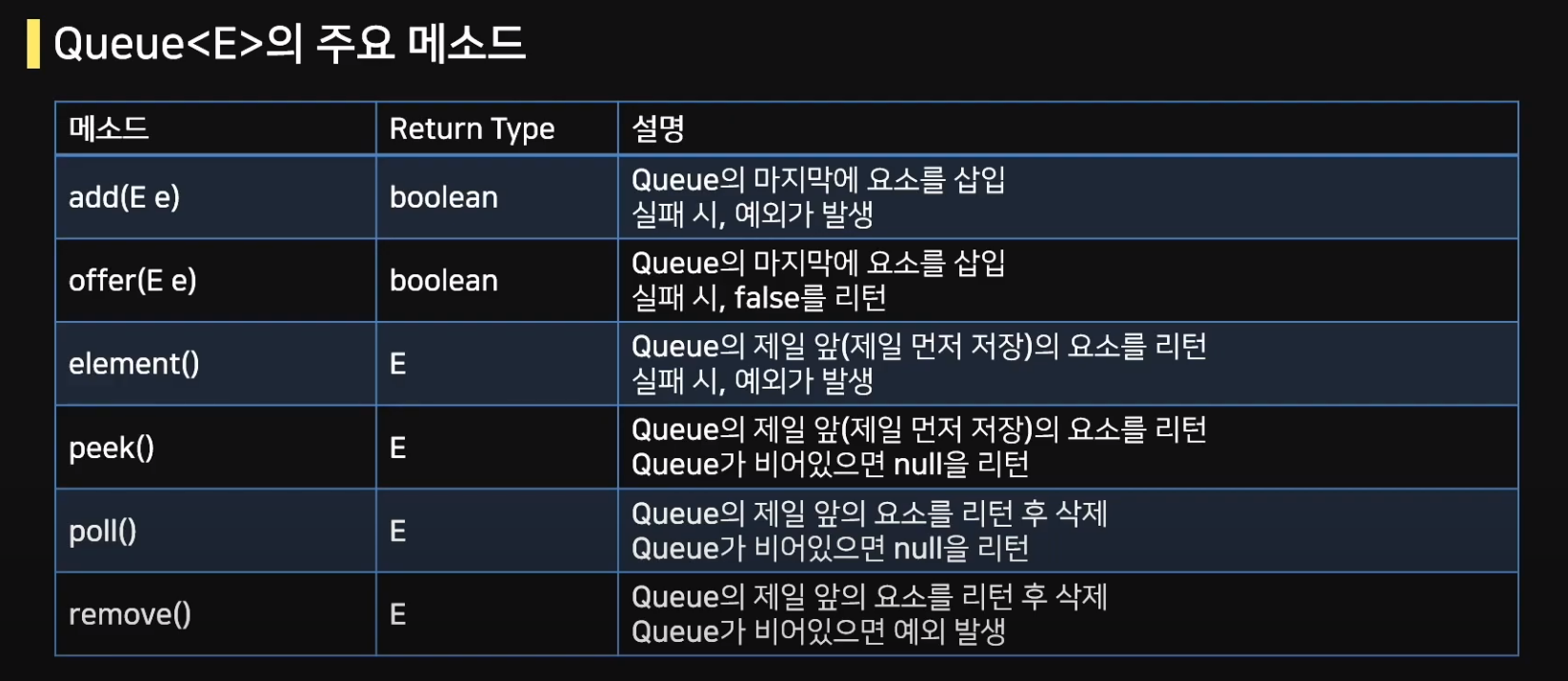
Queue의 주요메서드는 다음과 같다.
우선, queue에 삽입하는 메서드부터 보자. 두 메서드가 존재하는데 차이가 있다.
add(E e): 마지막에 요소를 삽입하지만 실패시 예외를 발생
offer(E e): 마지막에 요소를 삽입하지만 실패시 false를 리턴
따라서, 일반적으론 예외를 꺼려하기에 offer를 통해 삽입하는 것이 일반적이다.
여기서도 peek과 poll이 있는데 peek은 첫번째 요소를 반환만, poll은 반환후 삭제를 한다. 주목할 것은 remove와 poll
이다. 여기서는 remove()가 예외를 발생한다.
remove(): 첫번째 요소를 반환하고 Queue가 비어있으면 예외를 발생
poll(): 첫번째 요소를 반환하고 Queue가 비어있으면 null을 리턴
따라서, add()와 remove() 보단 offer와 poll을 사용하는게 좋을듯하다.
Priority Queue
자료의 우선순위에 따라, 출력되는 순서가 다른 자료구조.
Heap을 통해 구현되어 있어 이진트리 구조이다. O(NlogN)의 시간복잡도를 띈다.
대표적으론 MinHeap과 MaxHeap이 있다.
PQ에 삽입을 할때는 Heap의 제일 끝에 삽입 후 부모와 비교하는 과정을 거친다. (아래->위)
PQ에서 삭제를 할때는 Heap의 루트를 제거 후 -> 끝에 있는 노드를 루트로 올리고 -> 자식과 비교하는 과정을 거친다. (위->아래)
대부분 비교를 할때 사용하는 객체가 String, Integer이면 minheap, maxheap을 통한 비교가 쉽겠지만, 객체의 우선 순위를 직접 구현할 수도 있다.
이름과 나이를 가진 Person 객체가 있다고 가정하자.
static class Person implements Comparable<Person>{
private String name;
private int age;
//생성자 getter setter
@Override
public int compareTo(Person person) {
if(this.age==person.age){
return this.name.compareTo(person.name);
}
return this.age - person.age;
}
}위와 같이 구현하면 나이로 먼저 비교를 하고 나이가 동일할시 이름의 오름차순으로 정렬할 수 있다.
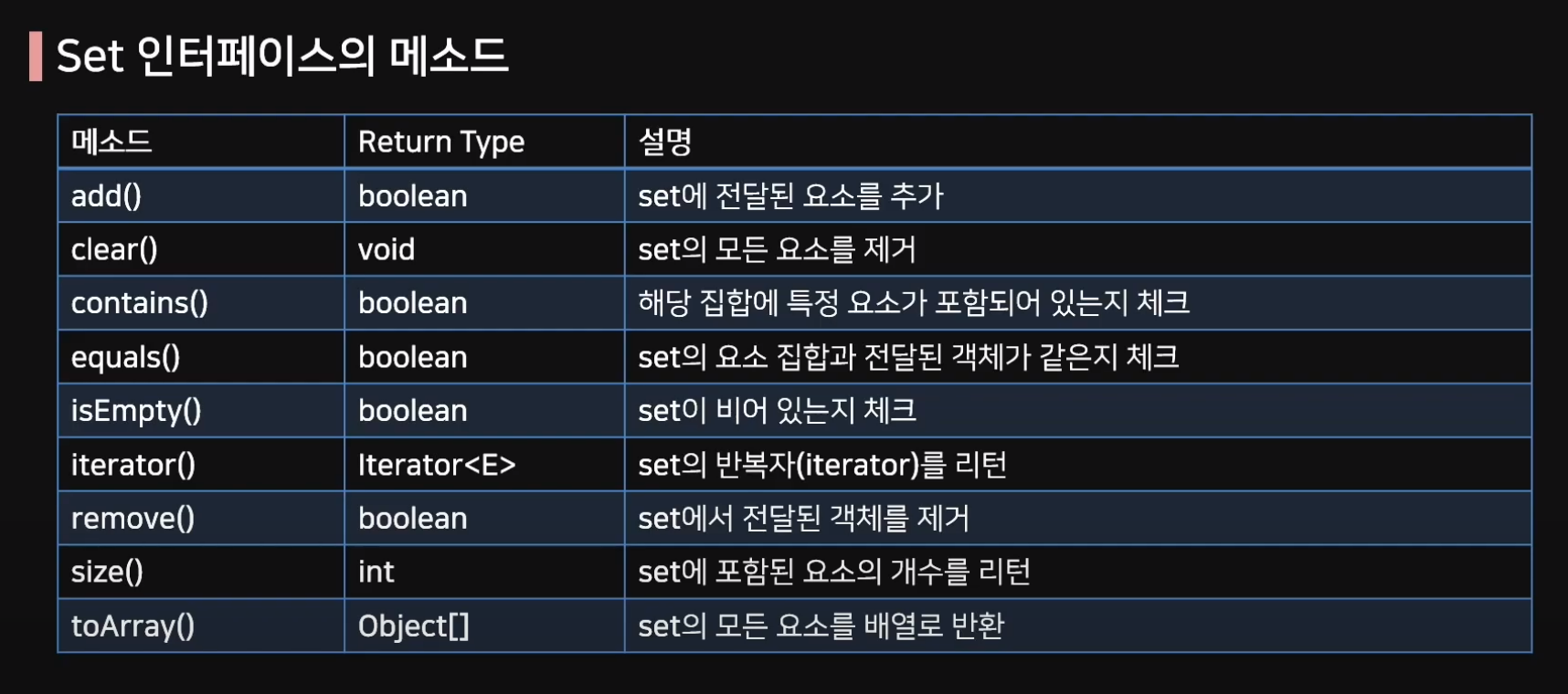
Set 인터페이스
순서 개념이 없는 컬렉션, 인덱스를 관리하지 않으며 중복된 값이 들어가지 않는다.
인덱스가 없기에 접근을 하기 위해선 iterator를 통해 접근해야한다.
HashSet
Set 인터페이스의 기본 구현체다. 중복이 없고 순서가 존재하지 않는다. 입력순서와 상관없이 어떠한 규칙, 해싱 알고리즘에 의해 값을 순서대로 반환한다. 즉, 순서가 없는게 아니라 순서를 보장하지 않는다는 말이 맞겠다.
구현을 보면 HashMap 기반으로 구현이 되어있다.
TreeSet
자료를 기본적으로 오름차순으로 정렬한다. 역시 중복 저장은 안되지만 정렬을 통해 어느정도의 순서의 개념을 활용할 수는 있다.
이진탐색트리를 기반으로 구현되어 추가,제거에 오래 걸리지만 정렬, 검색에 높은 성능을 띈다.
iterator를 사용할 수 있으며 iterator를 통해 내림차순으로 정렬 또한 가능하다.
itrator를 사용한 구현
Iterator<String> iterator = treeSet.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}itrator를 사용한 내림차순 구현
Iterator<String> iterator = treeSet.descendingIterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
LinkedHashSet
입력된 순서대로 데이터를 관리한다. LinkedList를 기반으로 하여 상대적으로 처리속도가 느리지만, 삽입 삭제에 용이하다.
'PL > 모던 자바 인 액션' 카테고리의 다른 글
| HashMap의 동작 구조 (0) | 2023.08.16 |
|---|---|
| Effectively final (0) | 2023.08.15 |
| 모던 자바 인 액션 스터디 - 2주차 (0) | 2023.08.15 |
| 모던 자바 인 액션 스터디 - 1주차 PDF (0) | 2023.08.09 |
| 모던 자바 인 액션 스터디 - 1주차 (0) | 2023.08.08 |
이번 시간엔, 자바의 컬렉션프레임워크에 대해 알아보자.
아래 그림과 같이 Iterable객체를 상속받은 Collection을 기반으로 다양한 컬렉션들이 존재한다. 대표적으론 List, Set, Map, Queue가 있다.
아래 그림외에도, Map이라는 컬렉션 또한 존재하는데 해당 컬렉션은 <Key, Value>로 이루어진 특별한 구조로 인해 별개로 구분한다.
List 인터페이스
순서 개념이 있는 데이터의 집합을 의미함. 순서가 존재하며 데이터의 중복저장이 가능하다.
이를 구현한 구현체로는 ArrayList, LinkedList, Vector, Stack이 존재한다.(Stack도 리스트 기반인줄은 .. 몰랐다)
ArrayList
내부적 배열을 기반한 단방향 포인터 구조로, 각 데이터의 인덱스가 존재한다. 내부적으로 배열을 이용하기에 크기조정을 하기 위해선 크기가 다른 배열을 생성하고 재배정하는 과정을 거친다.
주요 메서드는 아래 사진과 같은데 add메서드가 두 개 존재한다.
add(E e): 데이터를 끝에 추가하고 성공하면 true를 반환함
add(int index, E e): 데이터를 index번째 배열에 저장한다.
indexOf(E e): 해당 값이 존재하는 인덱스를 반환함.
LinkedList
노드끼리 연결된 연결리스트. List의 특징인 순서, 중복저장이 가능하다는 특징이 있다.
연결리스트인지라 중간에 데이터를 삽입/삭제하는데에 용이하지만 상대적으로 데이터를 조회하는데 속도가 느리다는 단점이 있다.
주요 메서드는 아래와 같은데 poll 메서드는 후에 삭제, peek은 보고끝!!을 기억하자.
offer(E o): 해당 값을 링크드리스트 끝에 ㅜㅊ가
peek(): 첫번째 요소를 리턴
poll(): 첫번쨰 요소를 리턴 후 삭제
Vector
기본적으로 ArrayList와 동일하다고 하다. 그러나, 여러개의 스레드가 데이터에 접근할때마다 동기화를 해주기에 Thread Safe하다는 특징을 가지고 있다.
물론, 스레드가 하나일때도 동기화가 진행되어 이 경우엔 성능이 저하된다.
capacity(): 벡터의 물리적인 크기를 반환한다. 메모리라고 생각했는데 기본 값이 10인것으로 보아 그건 아니다. 잘 쓰지 않는다고 한다!
Stack
후입 선출의 구조, 자료를 차례대로 넣고 뺄때는 나중에 넣은 값이 먼저 반환된다.
주요 메서드는 다음과 같은데 push, pop은 C++과 동일하지만 peek에 주목하자.
peek(): Stack에 마지막 요소를 리턴하고 끝 : 사실상 top()과 동일
pop(): Stack의 마지막 요소를 리턴하고 삭제
add()를 사용하기도 하는데 add는 boolean을 반환하고 push는 내가 입력한 파라미터를 반환한다는 것에도 주목하자. return type의 차이이다.
위의 자료들을 정렬하기 위해선 Collections에 sort함수를 사용하면 되며 기본적으론 오름차순으로 정렬한다.
Vector<String> vector = new Vector<>();
System.out.println(vector.capacity());
vector.add("가");
vector.add("다");
vector.add("나");
Collections.sort(vector);
for (String s: vector ) {
System.out.println(s);
}Queue 인터페이스
Queue는 대기열과 같은 선입선출 구조로 데이터를 일시적으로 쌓아둔다.
LinkedList를 활용하여 생성한다.
Queue의 주요메서드는 다음과 같다.
우선, queue에 삽입하는 메서드부터 보자. 두 메서드가 존재하는데 차이가 있다.
add(E e): 마지막에 요소를 삽입하지만 실패시 예외를 발생
offer(E e): 마지막에 요소를 삽입하지만 실패시 false를 리턴
따라서, 일반적으론 예외를 꺼려하기에 offer를 통해 삽입하는 것이 일반적이다.
여기서도 peek과 poll이 있는데 peek은 첫번째 요소를 반환만, poll은 반환후 삭제를 한다. 주목할 것은 remove와 poll
이다. 여기서는 remove()가 예외를 발생한다.
remove(): 첫번째 요소를 반환하고 Queue가 비어있으면 예외를 발생
poll(): 첫번째 요소를 반환하고 Queue가 비어있으면 null을 리턴
따라서, add()와 remove() 보단 offer와 poll을 사용하는게 좋을듯하다.
Priority Queue
자료의 우선순위에 따라, 출력되는 순서가 다른 자료구조.
Heap을 통해 구현되어 있어 이진트리 구조이다. O(NlogN)의 시간복잡도를 띈다.
대표적으론 MinHeap과 MaxHeap이 있다.
PQ에 삽입을 할때는 Heap의 제일 끝에 삽입 후 부모와 비교하는 과정을 거친다. (아래->위)
PQ에서 삭제를 할때는 Heap의 루트를 제거 후 -> 끝에 있는 노드를 루트로 올리고 -> 자식과 비교하는 과정을 거친다. (위->아래)
대부분 비교를 할때 사용하는 객체가 String, Integer이면 minheap, maxheap을 통한 비교가 쉽겠지만, 객체의 우선 순위를 직접 구현할 수도 있다.
이름과 나이를 가진 Person 객체가 있다고 가정하자.
static class Person implements Comparable<Person>{
private String name;
private int age;
//생성자 getter setter
@Override
public int compareTo(Person person) {
if(this.age==person.age){
return this.name.compareTo(person.name);
}
return this.age - person.age;
}
}위와 같이 구현하면 나이로 먼저 비교를 하고 나이가 동일할시 이름의 오름차순으로 정렬할 수 있다.
Set 인터페이스
순서 개념이 없는 컬렉션, 인덱스를 관리하지 않으며 중복된 값이 들어가지 않는다.
인덱스가 없기에 접근을 하기 위해선 iterator를 통해 접근해야한다.
HashSet
Set 인터페이스의 기본 구현체다. 중복이 없고 순서가 존재하지 않는다. 입력순서와 상관없이 어떠한 규칙, 해싱 알고리즘에 의해 값을 순서대로 반환한다. 즉, 순서가 없는게 아니라 순서를 보장하지 않는다는 말이 맞겠다.
구현을 보면 HashMap 기반으로 구현이 되어있다.
TreeSet
자료를 기본적으로 오름차순으로 정렬한다. 역시 중복 저장은 안되지만 정렬을 통해 어느정도의 순서의 개념을 활용할 수는 있다.
이진탐색트리를 기반으로 구현되어 추가,제거에 오래 걸리지만 정렬, 검색에 높은 성능을 띈다.
iterator를 사용할 수 있으며 iterator를 통해 내림차순으로 정렬 또한 가능하다.
itrator를 사용한 구현
Iterator<String> iterator = treeSet.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}itrator를 사용한 내림차순 구현
Iterator<String> iterator = treeSet.descendingIterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
LinkedHashSet
입력된 순서대로 데이터를 관리한다. LinkedList를 기반으로 하여 상대적으로 처리속도가 느리지만, 삽입 삭제에 용이하다.
'PL > 모던 자바 인 액션' 카테고리의 다른 글
| HashMap의 동작 구조 (0) | 2023.08.16 |
|---|---|
| Effectively final (0) | 2023.08.15 |
| 모던 자바 인 액션 스터디 - 2주차 (0) | 2023.08.15 |
| 모던 자바 인 액션 스터디 - 1주차 PDF (0) | 2023.08.09 |
| 모던 자바 인 액션 스터디 - 1주차 (0) | 2023.08.08 |